Whisper Batch Transcriber
A downloadable tool for Windows
Whisper Batch Transcriber
NOTE: Use this program instead, its better:
https://reactorcore.itch.io/parakeet-batch-transcriber
Whisper Batch Transcriber still works, but it will require a major overhaul, no ETA when I'll do it.
---
Automatically convert all of your voice recordings into clean, organized, neat text files.
It's fully automated, unlimited, using state-of-the-art speech-to-text technology. Works 100% offline on your computer, privately.
Convert speeches, podcasts, webinars, monologues, storytellings and other audio speech into a formatted .txt file. Here’s what a sample output looks like from a generated .mp3 file:
There are many different types of text that can be used just to fill space. Some of this text is about how people are treated unfairly in the world. People want to be free and have control over their own information, but it's not always easy. There are laws and rules that are supposed to protect people's rights, but they're not always followed. Ultimately, the goal is to be able to live our lives freely and make our own choices without being controlled or judged..
Usually it's one sentence per line, with a capitalized first letter and period at the end. Easy to read.
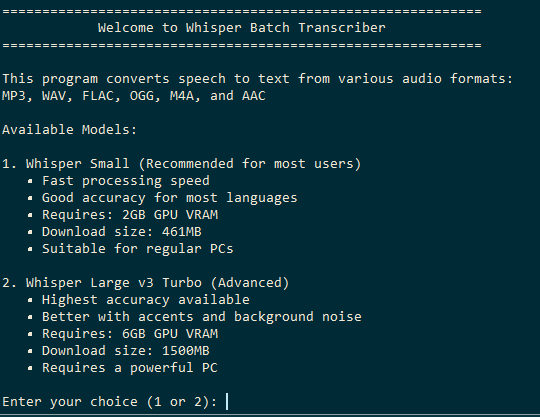
How to Use:
- Put your audio files into the folder called: 📂 put your audio files here
- Run the transcriber by double-clicking: ▶ whisper_transcriber.py
- The transcriptions will be saved as .txt files inside: 📂 output_transcripts
That's all! Easy as pie.
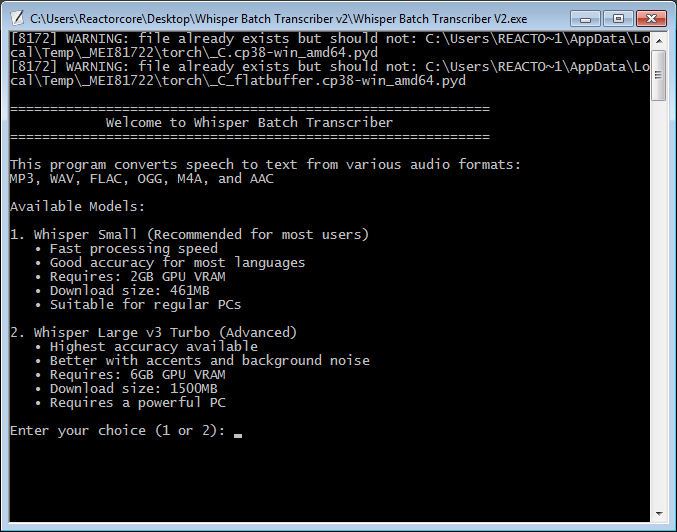
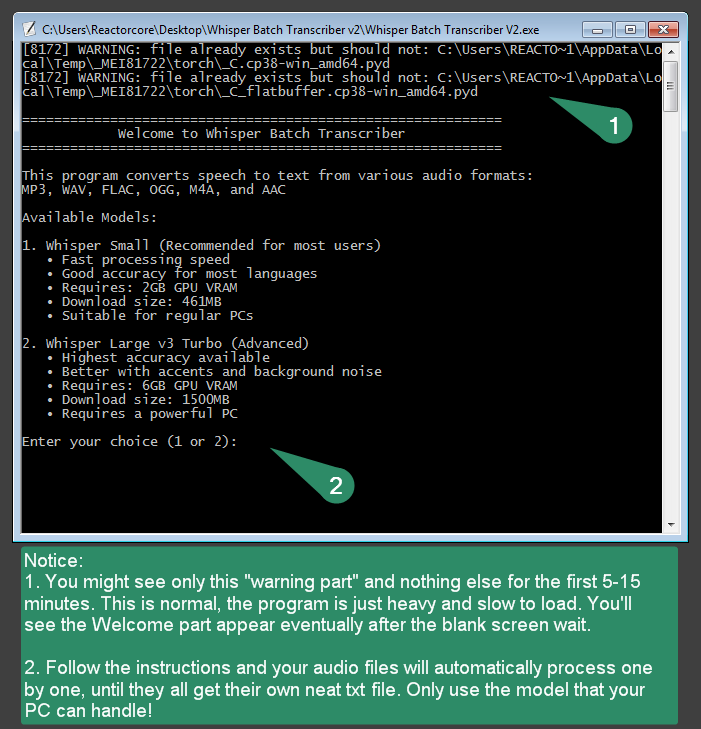
You can choose between two Whisper AI models:
- Small_en - requires 2GB of VRAM, 96% accuracy
- Large_v3_Turbo - requires 6GB of VRAM, 99,8% accuracy
The results with both models are REALLY GOOD. They’re relatively similar in speed, so if you do have a powerful enough computer to run Large_v3_turbo, then always use that.
Both models are pre-included in the package, so you don’t have to download them separately.
Install Info:
Before using this program, it requires having Python 3.10 or newer installed, plus a couple of script dependencies. You'll be running the program directly from the whisper_transcriber.py script file.
I've included a fully automatic one-time installer .exe that'll do the setup for you so that you'll be able to simply double-click the .py to run the program directly from hence forth.
The reason this is necessary is because I discovered compiling this python program into an exe actually makes it work slower than it would be if it was ran directly as a script.
Thankfully its easy to set up the system and I've made it as hassle-free and guided as possible. You'll find the needed info in the included Manual inside the folder.
System Requirements:
This program was tested on Windows 7, it requires 2GB of storage space and atleast a mid-range gaming Windows PC with a GPU that has a minimum of 2GB of VRAM, preferably more.
6GB or more GPU VRAM is necessary to run this program at its full potential.
NOTE: The program is slow to start. It can take about 5-15 minutes before it fully loads up; you'll first see a console window with two warnings and nothing else during this time but eventually the welcome screen will appear. This is normal.
Worth Knowing:
Accepted formats: ".mp3", ".wav", ".flac", ".ogg", ".m4a", ".aac"
Many audio files = Takes longer.
Longer audio files = Takes longer.
Files other than .wav = Takes longer.
Depending on your computer, 1 minute of audio can take about 2-10 minutes to process.
It will also use your CPU/RAM/VRAM to some degree, so you should let it work and not play performance-heavy 3D games in the background or do something else that is computationally expensive, like video editing. These activities can interfere with the process.
Accuracy and quality should be excellent, near perfect even, but mistakes can still happen. Use the Large-v3-Turbo model for best accuracy results.
I’d recommend throwing only about 120 minutes worth of audio into the program at a time, let it complete and then do another batch. Make sure to remove the previously completed copies of the audio files from the audio folder. There’s a chance the process might sometimes fail, so it’s best to not throw 100's of files and 10's of hours of audio all at once. Then again I haven't tested it with that many files, so it might actually work fine.
Protip: The program will run faster if your audio files are already .wav format, since that's the format the program actually needs to transcribe the speech-to-text. All other formats get converted into a temporary .wav file during the process so you can skip that if your files have been pre converted to a mono WAV file with a 16,000 Hz sample rate and 16-bit audio depth. Fre:ac, the free program to convert audio, can let you do this fairly easily.
Protip2: If your computer goes into sleep mode while this program is busy transcribing your files, you can prevent that by getting DontSleep.exe from SoftwareOk, a wonderful German software company:
https://www.softwareok.com/?seite=Microsoft/DontSleep
Credits for Whisper goes to OpenAI, Claude for coding assistance.
Other Transcribers:
https://offlinetranscribe.de/ (This uses the same underlying Whisper tech as mine, but is faster due to using a C++ version of it and it is more robust, but costs 50€/year.)
https://elevenlabs.io/blog/meet-scribe (Eleven Labs’ quality is EVEN BETTER than Whisper, but also costs $5/month per 12 hours of speech to text audio conversion. As of 2025, it's probably the BEST Speech-to-Text there is.)
The benefit of my program is that it's 100% free, unlimited, has good quality results, but is slower and less pretty.
Support My Work:

If you enjoyed this release, please buy me an orange to fuel me: https://buymeacoffee.com/reactorcoregames
Or join my Patreon for games, assets, design knowledge and tool recommendations: https://www.patreon.com/ReactorcoreGames
Check my Itch.io page and Follow me there to know when I release cool new stuff! https://reactorcore.itch.io/
All my links - I make games, software, assets, lego mechs, AI art and more: http://www.reactorcoregames.com
Join my Discord server to discuss my projects and get sneak peeks: https://discord.gg/UdRavGhj47
Another way to help me is to share my things with your friends, school, work, family or on social media. Every bit of visibility helps a lot!
Enjoy!
- Reactorcore
Download
Click download now to get access to the following files:

Comments
Log in with itch.io to leave a comment.
Program is broken for me. Guess what happens when I run the .py file?
Absolutely NOTHING. Fix your program or take this down.
I'm gonna need more information than that. What is your OS and PC specs? You are aware that the program takes a long time to load up - potentially even 15 minutes before you see the interface?
Right. Sorry for my directed anger btw.
My OS/PC specs: Windows 10 (ESU) Pro
CPU: i7-5870k
GPU: Nvidia 3060 RTX (12GB)
RAM: 64 GB DDR4
I've ran the .exe installer then double-clicked the whisper_transcriber.py and nothing has happened. I tried running it in cmd prompt, tried running it directly with Python interpreter... I went and made dinner and came back 2 hours later and it still hasn't launched. I don't know what I did wrong.
Thank you, this is useful information. Those specs are indeed plenty good enough to run both small and turbo v3 models so I suspect the issue is that the program might not be compatible with Windows 10 perhaps or the Whisper AI inference is being finicky that it fails to load, since while its running it spawns a bunch of files into temp files that might be bugging out for some reason. This was one of my earliest projects and I built it while on Windows 7 - my later programs are being developed on Win11, so they're better built.
I'm still busy with a lot of other work but reworking this program is on my todo list, perhaps even replacing it with a better one using NVIDIA's Parakeet transcription model - since its rumored to be better than Whisper. Lately I've been using my Elevenlabs Audio Transcriber since its far better in all ways possible, offering 2,5 hours of free high quality transcription each month or 12 hours for 5$, capturing different speakers, audio events and handling punctuation much better than Whisper ever could.
The Parakeet version I'm planning will be a free app, but I have no ETA on when it will be built/released.
As an alternative you can try these:
https://huggingface.co/spaces/nvidia/parakeet-tdt-0.6b-v2 (Free, but no Batch)
https://apps.microsoft.com/detail/9mtp065xxvbt?hl=en-US&gl=FI (Costs $12, but can do Batch)
Thank you so much for the assistance, I appreciate the thoughtful reply put into your response as both a developer and fellow coder.
I've had no issues running software before on Windows 10 so I'm thinking it could be a Python issue - My Python install is Python version 3.12 so I don't know if I need to update to the latest Python or not for this code to work as it was never specified
I run a lot of legacy software that still uses older versions of Python, so I'd need to run them in venvs with older versions of Python. Doable? Yes. PITA? Yes.
Thank you for the alternatives, I'll look into those. I have a 40 minute Twitch video I need to transcribe the audio from and turn into .SRT subtitles with timestamps, and my time crunch is short, so trying this and seeing it failing was driving me crazy. I'll give these a try. Cheers.
Ah, that must have been it, I didn't anticipate this at all. Since this Whisper Batch Transcriber was built while on Win7, I used Python 3.8, the last version that still worked on that OS, so its much older than even your python install - and now in hindsight of course most people aren't going to have that python version installed commonly, hence this conflict. Gah. I thought the program would work universally on all python versions 3.8 and above.
Well that sucks.
I asked Claude Code what the issue could be and it gave me this answer:
===
(I gave it the 'whisper_transcriber.py' file to analyze.)
Looking at your code, I can see a few potential issues on Python 3.12, though honestly it's pretty clean overall. Here's what to watch out for:
Actual Problems
1.
AudioSegment.from_file()with certain formats (indirect issue) Not Python 3.12 specific, butpydubdepends onffmpegbeing installed externally. This hasn't changed, but newer pydub versions have stricter error messages — worth noting in your docs if you haven't.2.
subprocess.check_output()incheck_vram()— minor but realresult = subprocess.check_output(['nvidia-smi', ...]) result.decode('utf-8').strip()On Python 3.12, this still works, but the bare
except:swallows everything includingKeyboardInterrupt. Not a crash risk, but bad practice that bites harder in 3.12 since it's stricter about interrupt propagation in some contexts. Should beexcept Exception:.The Real Culprit for User Issues
whisperitself and its dependencies are the likely problem, not your code. Specifically:whisperpackage depends ontorch, and PyTorch wheels for Python 3.8 vs 3.12 are completely different installspip install openai-whisperwill get a different (newer) torch version, which can behave differentlynumba(a whisper dependency) had broken 3.12 support for a while and required>=0.59.0What's Actually Fine
os.path,shutil,sys.frozenpatterns — all fine in 3.12time, file I/O,encoding='utf-8'— no issuesgetattr(sys, 'frozen', False)PyInstaller pattern — still worksRecommendation
Add a version check at the top and pin your dependencies in a
requirements.txt:import sys if sys.version_info < (3, 8) or sys.version_info >= (3, 13): print("Warning: This script is tested on Python 3.8–3.12 only.")The bare
except:incheck_vram()is the only real code-level fix needed. Everything else is dependency/environment friction, not your Python syntax.===
I dunno if that's useful tbh.
I think you're ultimately right, I need to take down this project since its only going to work on a niche installation setup - because I didn't understand python properly at the time.
I'll make the much better Parakeet based version in the future to replace it, Whisper is already very dated anyways.